Once you have migrated your data from Access to SQL Server, you now have a client/server database, which may be an on-premises or a hybrid Azure cloud solution. Either way, Access is now the presentation layer and SQL Server is the data layer. Now is a good time to re-think aspects of your solution, especially query performance, security, and business continuity, so you can improve and scale your database solution.
For an Access user to first meet the SQL Server and Azure documentation may feel daunting. This calls for a tour guide to take you through the highlights that matter to you. Once you finish this excursion, you'll be ready to explore the advances in database technology and take a longer journey.
In this Article
| Database Management | Queries and related | Data Types | Sundry |
Drive business continuity
For your Access solution, you want to keep it up and running with minimal interruption, but your options with an Access back-end database are limited. Backing up your Access database is essential for protecting your data, but it requires taking your users offline. Then there is unplanned downtime caused by hardware/software maintenance upgrades, network or power outages, hardware failure, security breaches, or even cyberattacks. To minimize the downtime and impact to your business, you can back up an SQL Server database while it is in use. In addition, SQL Server also offers high availability (HA) and disaster recovery (DR) strategies. These two combined technologies are called HADR. For more information, see Business continuity and database recovery and Drive business continuity with SQL Server (e-book).
Backup while in use
SQL Server uses an online backup process that can occur while the database is running. You can do a full backup, a partial backup, or a file backup. A backup copies data and transaction logs to ensure a complete restore operation. Especially in an on-premises solution, be aware of the differences between simple and full recovery options and how they affect transaction log growth. For more information, see Recovery Models.
Most backup operations occur right away, except file-management and shrink database operations. Conversely, if you try to create or delete a database file while a backup operation is in progress, the operation fails. For more information, see Backup Overview.
HADR
The two most common techniques for achieving high availability and business continuity are mirroring and clustering. SQL Server integrates mirroring and clustering technology with "Always On Failover Cluster Instances" and "Always On Availability Groups".
Mirroring is a database-level continuity solution that supports near-instant failover by maintaining a standby database, a full copy or mirror of the active database on separate hardware. It can operate in a synchronous (high safety) mode, where an incoming transaction is committed to all servers at the same time, or in an asynchronous (high performance) mode, where an incoming transaction is committed to the active database and then at some pre-determined point copied over to the mirror. Mirroring is a database-level solution and works only with databases that use the full recovery model.
Clustering is a server-level solution that combine servers into a single data storage that looks to the user like a single instance. Users connect to the instance and never need to know which server in the instance is currently active. If one server fails or needs to be taken offline for maintenance, the user experience doesn't change. Each server in the cluster is monitored by the cluster manager using a heartbeat, so it detects when the active server in the cluster goes offline and attempts to seamlessly switch to the next server in the cluster, although there is a variable time delay as the switch happens.
For more information, see Always On Failover Cluster Instances and Always On availability groups: a high-availability and disaster-recovery solution.
SQL Server Security
Although you can protect your Access database by using the Trust Center and by encrypting the database, SQL Server has more advanced security features. Let's look at three capabilities that stand out for the Access user. For more information, see Securing SQL Server.
Database authentication
There are four database authentication methods in SQL Server, each of which you can specify in an ODBC connection string. For more information, see Link to or import data from an Azure SQL Server Database. Each method has its own benefits.
Integrated Windows authentication Use Windows credentials for user validation, security roles and limiting users to features and data. You can leverage domain credentials and easily manage user rights in your application. Optionally, enter a Service Principal Names (SPNs). For more information, see Choose an Authentication Mode.
SQL Server Authentication Users need to connect with credentials that have been set up in the database by entering the login ID and password the first time they access the database in a session. For more information, see Choose an Authentication Mode.
Azure Active Directory Integrated authentication Connect to the Azure SQL Server Database by using Azure Active Directory. Once you have configured Azure Active Directory authentication, no additional login and password is required. For more information, see Connecting to SQL Database by Using Azure Active Directory Authentication.
Active Directory Password authentication Connect with credentials that have been set up in the Azure Active Directory by entering the login name and password. For more information, see Connecting to SQL Database by Using Azure Active Directory Authentication.
Tip Use Threat Detection to receive alerts on anomalous database activity indicating potential security threats to an Azure SQL Server database. For more information, see SQL Database Threat Detection.
Application security
SQL Server has two application-level security features that you can take advantage of with Access.
Dynamic Data Masking Conceal sensitive information by masking it from non-privileged users. For example, you can mask Social Security numbers, either partially or in full.
 A partial data mask |  A full data mask |
There are several ways you can define a data mask and you can apply them to different data types. Data masking is policy-driven at the table and column level for a defined set of users and is applied in real-time to query. For more information, see Dynamic Data Masking.
Row-level Security You can control access to specific database rows with sensitive information based on user characteristics by using Row-Level Security. The database system applies these access restrictions and this makes the security system more reliable and robust.

There are two types of security predicates:
-
A filter predicate filters rows from a query. The filter is transparent, and the end user is unaware of any filtering.
-
A block predicate prevents unauthorized action and throws an exception if the action can't be performed.
For more information, see Row level security.
Protecting Data with Encryption
Safeguard data at rest, in transit, and while in use without affecting database performance. For more information, see SQL Server Encryption.
Encryption at rest To secure personal data against offline media attacks at the physical storage layer, use encryption-at-rest, also called Transparent Data Encryption (TDE). This means your data is protected even if the physical media is stolen or improperly disposed. TDE performs real-time encryption and decryption of databases, backups, and transaction logs without requiring any change to your applications.
Encryption in transit To protect against snooping and"man-in-the-middle attacks", you can encrypt data transmitted across the network. SQL Server supports Transport Layer Security (TLS) 1.2 for highly secure communications. The Tabular Data Stream (TDS) protocol is also used to protect communications over untrusted networks.
Encryption in use on the client To protect personal data while in use, "Always Encrypted" is the feature you want. Personal data is encrypted and decrypted by a driver on the client computer without revealing encryption keys to the database engine. As a result, encrypted data is only visible to the people responsible for managing that data, and not other highly privileged users who shouldn't have access. Depending on the type of encryption selected, Always Encrypted may limit some database functionality like searching, grouping, and indexing of encrypted columns.
Handle privacy concerns
Privacy concerns are so widespread that the European Union has defined legal requirements through the General Data Protection Regulation (GDPR). Fortunately, an SQL Server back-end is well suited to respond to these requirements. Think of implementing GDPR in a three-step framework.

Step 1: Assess and manage compliance risk
GDPR requires you to identify and inventory the personal information you have in tables and files. This information can be anything from a name, a photo, an email address, bank details, posts on social networking web sites, medical information, or even an IP address.
A new tool, SQL Data Discovery and Classification, built into SQL Server Management Studio helps you discover, classify, label, and report on sensitive data by applying two metadata attributes to columns:
-
Labels To define the sensitivity of data.
-
Information types To provide additional granularity about the types of data stored in a column.
Another discovery mechanism you can use is full-text search, which includes the use of CONTAINS and FREETEXT predicates and rowset-valued functions like CONTAINSTABLE and FREETEXTTABLE for use with the SELECT statement. Using full-text search, you can search tables to discover words, word combinations, or variations of a word such as synonyms or inflectional forms. For more information, see Full-Text Search.
Step 2: Protect personal information
GDPR requires you to secure personal information and limit access to it. In addition to the standard steps you take to manage access to your network and resources, like firewall settings, you can use SQL Server security features to help you control data access:
-
SQL Server authentication to manage user identity and prevent unauthorized access.
-
Row-Level Security to limit access to rows in a table based on the relationship between the user and that data.
-
Dynamic Data Masking to limit exposure to personal data by masking it from non-privileged users.
-
Encryption to ensure that personal data is protected during transmission and storage and is protected against compromise, including on the server side.
For more information, see SQL Server Security.
Step 3: Respond efficiently to requests
GDPR requires you to maintain records of personal-data processing and make these records available to supervisory authorities upon request. If issues including accidental data release occur, protection controls allow you to respond quickly. Data must be quickly available when reporting is needed. For example, GDPR requires that a personal-data breach be reported to the supervisory authority "not later than 72 hours after having become aware of it."
SQL Server 2017 assists you with reporting tasks in several ways:
-
SQL Server Audit helps you ensure that persistent records of database access and processing activities exist. It performs a fine-grained audit that tracks database activities to help you understand and identify potential threats, suspected abuse, or security violations. You can readily perform data forensics.
-
SQL Server temporal tables are system-versioned user tables designed to keep a full history of data changes. You can use these for easy reporting and point-in-time analysis.
-
SQL Vulnerability Assessment helps you detect security and permissions issues. When an issue is detected, you can also drill down into database scan reports to find actions for resolution.
For more information, see Create a platform of trust (e-book) and Journey to GDPR Compliance.
Create database snapshots
A database snapshot is a read-only, static view of a SQL Server database at a point in time. Although you can copy an Access database file to effectively create a database snapshot, Access does not have a built-in methodology as SQL Server. You can use a database snapshot for writing reports based on the data at the time of the database snapshot creation. You can also use a database snapshot to maintain historical data, such as one for each financial quarter that you use to roll up end-of-period reports. We recommend the following best practices:
-
Name the snapshot Each database snapshot requires a unique database name. Add the purpose and timeframe to the name for easier identification. For example, to snapshot the AdventureWorks database three times a day at 6-hour intervals between 6 A.M. and 6 P.M. based on a 24-hour clock, name them AdventureWorks_snapshot_0600, AdventureWorks_snapshot_1200, and AdventureWorks_snapshot_1800.
-
Limit the number of snapshots Each database snapshot persists until it is explicitly dropped. Because each snapshot will continue to grow, you may want to conserve disk space by deleting an older snapshot after creating a new snapshot. For example, if you are making daily reports, keep the database snapshot for 24 hours, and then drop and replace it with a new one.
-
Connect to the correct snapshot To use a database snapshot, the Access front-end needs to know the correct location. When you substitute a new snapshot for an existing one, you need to redirect Access to the new snapshot. Add logic to the Access front-end to make sure you are connecting to the correct database snapshot.
Here's how you create a database snapshot:
CREATE DATABASE AdventureWorks_dbss1800 ON ( NAME = AdventureWorks_Data, FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Data\AdventureWorks_snapshot_0600' ) AS SNAPSHOT OF AdventureWorks;
For more information, see Database Snapshots (SQL Server).
Concurrency control
When many people attempt to modify data in a database at the same time, a system of controls is needed so that modifications made by one person do not adversely affect those of another person. This is called concurrency control and there are two basic locking strategies, pessimistic and optimistic. Locking can prevent users from modifying data in a way that affects other users. Locking also helps ensure database integrity, especially with queries that otherwise might produce unexpected results. There are important differences in the way Access and SQL Server implement these concurrency control strategies.
In Access, the default locking strategy is optimistic and grants ownership of the lock to the first person to attempt to write to a record. Access displays the Write Conflict dialog box to the other person attempting to write to the same record at the same time. To resolve the conflict, the other person can save the record, copy it to the clipboard, or drop the changes.
You can also use the RecordLocks property to change the concurrency control strategy. This property affects forms, reports, and queries and has three settings:
-
No Locks In a form, users can attempt to edit the same record simultaneously but the Write Conflict dialog box may appear. In a report, records aren't locked while the report is previewed or printed. In a query, records aren't locked while the query is run. This is the Access way to implement optimistic locking.
-
All Records All records in the underlying table or query are locked while the form is open in Form view or Datasheet view, while the report is previewed or printed, or while the query is run. Users can read the records during the lock.
-
Edited Record For forms and queries, a page of records is locked as soon as any user starts editing any field in the record and stays locked until the user moves to another record. Consequently, a record can be edited by only one user at a time. This is the Access way to implement pessimistic locking.
For more information, see Write Conflict dialog box and RecordLocks Property.
In SQL Server, concurrency control works this way:
-
Pessimistic After a user performs an action that causes a lock to be applied, other users cannot perform actions that would conflict with the lock until the owner releases it. This concurrency control is mainly used in environments where there is high contention for data.
-
Optimistic In optimistic concurrency control, users do not lock data when they read it. When a user updates data, the system checks to see if another user changed the data after it was read. If another user updated the data, an error is raised. Typically, the user receiving the error rolls back the transaction and starts over. This concurrency control is mainly used in environments where there is low contention for data.
You can specify the type of concurrency control by selecting several transaction isolation levels, which define the level of protection for the transaction from modifications made by other transactions by using the SET TRANSACTION statement:
SET TRANSACTION ISOLATION LEVEL { READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SNAPSHOT | SERIALIZABLE } | Isolation level | Description |
| Read uncommitted | Transactions are isolated only enough to ensure that physically corrupt data is not read. |
| Read committed | Transactions can read data previously read by another transaction without waiting for the first transaction to complete. |
| Repeatable read | Read and write locks occur on selected data until the end of the transaction, but phantom reads may occur. |
| Snapshot | Uses row version to provide transaction-level read consistency. |
| Serializable | Transactions are completely isolated from one another. |
For more information, see Transaction Locking and Row Versioning Guide.
Improve query performance
Once you have an Access pass-through query working, take advantage of the sophisticated ways SQL Server can make it run more efficiently.
Unlike an Access database, SQL Server provides parallel queries to optimize query execution and index operations for computers that have more than one microprocessor (CPU). Because SQL Server can perform a query or index operation in parallel by using several system worker threads, the operation can be completed quickly and efficiently.
Queries are a critical component of improving the overall performance of your database solution. Bad queries run indefinitely, timeout, and use up resources like CPUs, memory, and network bandit. This hinders the availability of critical business information. Even one bad query can cause serious performance issues for your database.
For more information, see Faster querying with SQL Server (e-book).
Query optimization
Several tools work together to help you analyze a query's performance and improve it: Query Optimizer, execution plans, and Query Store.
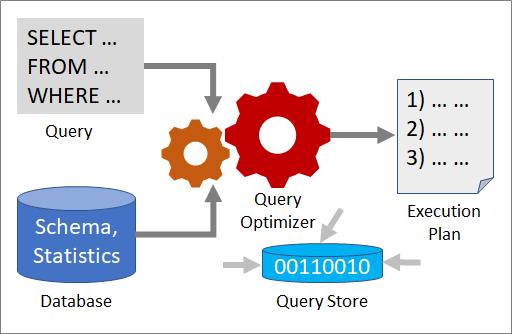
Query optimizer
The Query Optimizer is one of the most important components of SQL Server. Use the Query Optimizer to analyze a query and determine the most efficient way to access the required data. The input to the Query Optimizer consists of the query, the database schema (table and index definitions), and database statistics. The output of the Query Optimizer is an execution plan.
For more information, see The SQL Server Query Optimizer.
Execution plan
An execution plan is a definition that sequences the source tables to access and the methods used to extract data from each table. Optimization is the process of selecting one execution plan from potentially many possible plans. Each possible execution plan has an associated cost in the amount of computing resources used and Query Optimizer chooses the one with the lowest estimated cost.
SQL Server must also dynamically adjust to changing conditions in the database. Regressions in query execution plans can greatly impact performance. Certain changes in a database can cause an execution plan to be either inefficient or invalid, based on the new state of the database. SQL Server detects the changes that invalidate an execution plan and marks the plan as not valid.
A new plan must then be recompiled for the next connection that executes the query. The conditions that invalidate a plan include:
-
Changes made to a table or view referenced by the query (ALTER TABLE and ALTER VIEW).
-
Changes to indexes used by the execution plan.
-
Updates on statistics used by the execution plan, generated either explicitly from a statement, such as UPDATE STATISTICS, or automatically.
For more information, see Execution plans.
Query Store
Query Store provides insight on execution plan choice and performance. It simplifies performance troubleshooting by helping you quickly find performance differences caused by execution plan changes. Query Store gathers telemetry data, such as a history of queries, plans, runtime statistics, and wait statistics. Use the ALTER DATABASE statement to implement the Query Store:
ALTER DATABASE AdventureWorks2012 SET QUERY_STORE = ON;
For more information, see Monitoring performance by using the Query Store.
Automatic Plan Correction
Perhaps the easiest way to improve query performance is with Automatic Plan Correction, which is a feature available with Azure SQL Database. You just turn it on and let it work. It continuously performs execution plan monitoring and analysis, detects problematic execution plans, and automatically fixes performance problems. Behind the scenes, Automatic Plan Correction uses a four-step strategy of learn, adapt, verify, and repeat.
For more information, see Automatic tuning.
Adaptive Query Processing
You can also get faster queries just by upgrading to SQL Server 2017, which has a new feature called adaptive query processing. SQL Server adjusts query plan choices based on runtime characteristics.
Cardinality estimation approximates the number of rows processed at each step in an execution plan. Inaccurate estimations can result in slow query response time, unnecessary resource utilization (memory, CPU, and IO), and reduced throughput and concurrency. Three techniques are used to adapt to application workload characteristics:
-
Batch mode memory grant feedback Poor cardinality estimates can cause queries to "spill to disk" or take too much memory. SQL Server 2017 adjusts memory grants based on execution feedback, removes spills to disk, and improves concurrency for repeating queries.
-
Batch mode adaptive joins Adaptive joins dynamically select a better internal join type (nested loop joins, merge joins or hash joins) during runtime, based on actual input rows. Consequently, a plan can dynamically switch to a better join strategy during execution.
-
Interleaved execution Multi-statement table valued functions have traditionally been treated as a black box by query processing. SQL Server 2017 can better estimate row counts to improve downstream operations.
You can make workloads automatically eligible for adaptive query processing by enabling a compatibility level of 140 for the database:
ALTER DATABASE [YourDatabaseName] SET COMPATIBILITY_LEVEL = 140;
For more information, see Intelligent query processing in SQL databases.
Ways to query
In SQL Server there are several ways to query, and they each have their benefits. You want to know what they are, so you can make the right choice for your Access solution. The best way to create your TSQL queries is to interactively edit and test them by using the SQL Server Management Studio (SSMS) Transact-SQL editor, which has intellisense to help you choose the right keywords and check for syntax errors.
Views
In SQL Server, a view is like a virtual table where the view data comes from one or more tables or other views. However, views are referenced just like tables in queries. Views can hide the complexity of queries and help protect data by limiting the set of rows and columns. Here's an example of a simple view:
CREATE VIEW HumanResources.EmployeeHireDate AS SELECT p.FirstName, p.LastName, e.HireDate FROM HumanResources.Employee AS e JOIN Person.Person AS p ON e.BusinessEntityID = p.BusinessEntityID;
For optimal performance and to edit the view results, create an indexed view, which persists in the database like a table, has storage allocated for it, and can be queried like any table. To use it in Access, link to the view in the same way you link to a table. Here's an example of an indexed view:
CREATE VIEW Sales.vOrders WITH SCHEMABINDING AS SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue, OrderDate, ProductID, COUNT_BIG(*) AS COUNT FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o WHERE od.SalesOrderID = o.SalesOrderID GROUP BY OrderDate, ProductID; CREATE UNIQUE CLUSTERED INDEX IDX_V1 ON Sales.vOrders (OrderDate, ProductID);
There are restrictions, however. You can't update data if more than one base table is affected or the view contains aggregate functions or a DISTINCT clause. If SQL Server returns an error message saying it does not know which record to delete, you may need to add a delete trigger on the view. Finally, you can't use the ORDER BY clause as you can with an Access query.
For more information, see Views and Create indexed Views.
Stored procedures
A stored procedure is a group of one or more TSQL statements that take input parameters, return output parameters, and indicate success or failure with a status value. They act as an intermediate layer between the Access front-end and the SQL Server back-end. Stored procedures can be as simple as a SELECT statement or as complex as any program. Here's an example:
CREATE PROCEDURE HumanResources.uspGetEmployees @LastName nvarchar(50), @FirstName nvarchar(50) AS SET NOCOUNT ON; SELECT FirstName, LastName, Department FROM HumanResources.vEmployeeDepartmentHistory WHERE FirstName = @FirstName AND LastName = @LastName AND EndDate IS NULL;
When you use a stored procedure in Access, it usually returns a result set back to a form or report. However, it may perform other actions that don't return results, such as DDL or DML statements. When you use a pass-through query, make sure you set the Returns Records property appropriately.
For more information, see Stored procedures.
Common Table Expressions
A Common Table Expressions (CTE) is like a temporary table that generates a named result set. It exists only for the execution of a single query or DML statement. A CTE is built in the same code line as the SELECT statement or the DML statement that uses it, whereas creating and using a temporary table or view is usually a two-step process. Here's an example:
-- Define the CTE expression name and column list. WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear) AS -- Define the CTE query. ( SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear FROM Sales.SalesOrderHeader WHERE SalesPersonID IS NOT NULL ) -- Define the outer query referencing the CTE name. SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear FROM Sales_CTE GROUP BY SalesYear, SalesPersonID ORDER BY SalesPersonID, SalesYear;
A CTE has several benefits including the following:
-
Because CTEs are transient, you don't have to create them as permanent database objects like views.
-
You can reference the same CTE more than once in a query or DML statement, making your code more manageable.
-
You can use queries that reference a CTE to define a cursor.
For more information, see WITH common_table_expression.
User-Defined Functions
A User-defined function (UDF) can perform queries and calculations and return either scalar values or data result sets. They are like functions in programming languages that accept parameters, perform an action such as a complex calculation, and return the result of that action as a value. Here's an example:
CREATE FUNCTION dbo.ISOweek (@DATE datetime) RETURNS int WITH SCHEMABINDING -- Helps improve performance WITH EXECUTE AS CALLER AS BEGIN DECLARE @ISOweek int; SET @ISOweek= DATEPART(wk,@DATE)+1 -DATEPART(wk,CAST(DATEPART(yy,@DATE) as CHAR(4))+'0104'); -- Special cases: Jan 1-3 may belong to the previous year IF (@ISOweek=0) SET @ISOweek=dbo.ISOweek(CAST(DATEPART(yy,@DATE)-1 AS CHAR(4))+'12'+ CAST(24+DATEPART(DAY,@DATE) AS CHAR(2)))+1; -- Special case: Dec 29-31 may belong to the next year IF ((DATEPART(mm,@DATE)=12) AND ((DATEPART(dd,@DATE)-DATEPART(dw,@DATE))>= 28)) SET @ISOweek=1; RETURN(@ISOweek); END; GO SET DATEFIRST 1; SELECT dbo.ISOweek(CONVERT(DATETIME,'12/26/2004',101)) AS 'ISO Week';
A UDF does have certain limitations. For example, they can't use certain nondeterministic system functions, perform DML or DDL statements, or do dynamic SQL queries.
For more information, see User Defined Functions.
Add keys and indexes
Whatever database system you use, keys and indexes go hand-in-hand.
Keys
In SQL Server, make sure you create primary keys for each table and foreign keys for each related table. The equivalent feature in SQL Server to the Access AutoNumber data type is the IDENTITY property, which can be used to creating key values. Once you apply this property to any numeric column, it becomes read-only and maintained by the database system. When you insert a record into a table that contains an IDENTITY column, the system automatically increments the value for the IDENTITY column by 1 and starting from 1, but you can control these values with arguments.
For more information, see CREATE TABLE, IDENTITY (Property).
Indexes
As always, the selection of indexes is a balancing act between query speed and update cost. In Access, you have one type of index, but in SQL Server you have twelve. Fortunately, you can use the query optimizer to help you reliably choose the most effective index. And in Azure SQL, you can use automatic index management, a feature of automatic tuning, which recommends the adding or removing of indexes for you. Unlike Access, you must create your own indexes for foreign keys in SQL Server. You can also create indexes on an indexed view to improve query performance. The downside to an indexed view is increased overhead when you modify data in the view's base tables, because the view must be updated as well. For more information, see SQL Server Index Architecture and Design Guide and Indexes.
Perform transactions
Performing an Online Transaction Process (OLTP) is difficult when using Access, but relatively easy with SQL Server. A transaction is a single unit of work that commits all data changes when successful but rolls back the changes when unsuccessful. A transaction must have four properties, often referred to as ACID:
-
Atomicity A transaction must be an atomic unit of work; either all its data modifications are performed, or none are performed.
-
Consistency When completed, a transaction must leave all data in a consistent state. This means all data integrity rules are applied.
-
Isolation Changes made by concurrent transactions are isolated from the current transaction.
-
Durability After a transaction has completed, changes are permanent even in the event of a system failure.
You use a transaction to ensure guaranteed data integrity, such as an ATM cash withdrawal or automatic deposit of a paycheck. You can do explicit, implicit, or batch-scoped transactions. Here are two, TSQL examples:
-- Using an explicit transaction BEGIN TRANSACTION; DELETE FROM HumanResources.JobCandidate WHERE JobCandidateID = 13; COMMIT; -- the ROLLBACK statement rolls back the INSERT statement, but the created table still exists. CREATE TABLE ValueTable (id int); BEGIN TRANSACTION; INSERT INTO ValueTable VALUES(1); INSERT INTO ValueTable VALUES(2); ROLLBACK;
For more information, see Transactions.
Using constraints and triggers
All databases have ways to maintain data integrity.
Constraints
In Access, you enforce referential integrity in a table relationship through foreign key-primary key pairings, cascading updates and deletes, and validation rules. For more information, see Guide to table relationships and Restrict data input by using validation rules.
In SQL Server, you use UNIQUE and CHECK constraints, which are database objects that enforce data integrity in SQL Server tables. To validate that a value is valid in another table, use a foreign key constraint. To validate that a value in a column is within a specific range, use a check constraint. These objects are your first line of defense and are designed to work efficiently. For more information, see Unique Constraints and Check Constraints.
Triggers
Access does not have database triggers. In SQL Server, you can use triggers to enforce complex data integrity rules and to run this business logic on the server. A database trigger is a stored procedure that runs when specific actions occur within a database. The trigger is an event, such as adding or deleting a record to a table, that fires and then executes the stored procedure. Although an Access database can ensure referential integrity when a user attempts to update or delete data, SQL Server has a sophisticated set of triggers. For example, you can program a trigger to delete records in bulk and ensure data integrity. You can even add triggers to tables and views.
For more information, see Triggers - DML, Triggers - DDL and Designing a T-SQL trigger.
Use computed columns
In Access, you create a calculated column by adding it to a query and building an expression, such as:
Extended Price: [Quantity] * [Unit Price]
In SQL Server, the equivalent feature is called a computed column, which is a virtual column that is not physically stored in the table, unless the column is marked PERSISTED. Like a calculated column, a computed column uses data from other columns in an expression. To create a computed column, add it to a table. For example:
CREATE TABLE dbo.Products ( ProductID int IDENTITY (1,1) NOT NULL , QtyAvailable smallint , UnitPrice money , InventoryValue AS QtyAvailable * UnitPrice );
For more information, see Specify Computed Columns in a Table.
Time stamp your data
You sometimes add a table field to record a time stamp when a record is created so you can log the data entry. In Access, you can simply create a date column with the default value of =Now(). To record a date or time in SQL Server, use the datetime2 data type with the default value of SYSDATETIME().
Note Avoid confusing rowversion with adding a timestamp to your data. The keyword timestamp is a synonym for rowversion in SQL Server, but you should use the keyword rowversion. In SQL Server, rowversion is a data type that exposes automatically generated, unique binary numbers within a database, and is generally used as a mechanism for version-stamping table rows. However, the rowversion data type is just an incrementing number, does not preserve a date or a time, and is not designed for timestamping a row.
For more information, see rowversion. For more information about using rowversion to minimize record conflicts, see Migrate an Access database to SQL Server.
Manage large objects
In Access you manage unstructured data, such as files, photos, and images, by using the Attachment data type. In SQL Server terminology, unstructured data is called a Blob (Binary Large Object) and there are several ways to work with them:
FILESTREAM Uses the varbinary(max) data type to store the unstructured data on the file system rather than the database. For more information, see Access FILESTREAM Data with Transact-SQL.
FileTable Stores blobs in special tables called FileTables and provides compatibility with Windows applications as if they were stored in the file system and without making any changes to your client applications. FileTable requires the use of FILESTREAM. For more information, see FileTables.
Remote BLOB store (RBS) Stores binary large objects (BLOBs) in commodity storage solutions instead of directly on the server. This saves space and reduces hardware resources. For more information, see Binary Large Object (Blob) Data.
Work with hierarchical data
Although relational databases such as Access are very flexible, working with hierarchical relationships is an exception and often requires complex SQL statements or code. Examples of hierarchical data include: an organizational structure, a file system, a taxonomy of language terms, and a graph of links between Web pages. SQL Server has a built-in hierarchyid data type and set of hierarchical functions to easily store, query, and manage hierarchical data.
For more information, see Hierarchical data and Tutorial: Using the hierarchyid data type.
Manipulate JSON text
JavaScript Object Notation (JSON) is a web service that uses human-readable text to transmit data as attribute–value pairs in asynchronous browser–server communication. For example:
{ "firstName": "Mary", "lastName": "Contrary", "spouse": null, "age": 27 } Access does not have any built-in ways to manager JSON data, but in SQL Server you can smoothly store, index, query, and extract JSON data. You can convert and store JSON text in a table or format data as JSON text. For example, you may want to format query results as JSON for a Web app or add JSON data structures into rows and columns.
Note JSON is not supported in VBA. As an alternative, you can use XML in VBA by using the MSXML library.
For more information, see JSON data in SQL Server.
Resources
Now is a great time to learn more about SQL Server and Transact SQL (TSQL). As you've seen, there are many features like Access, but also capabilities Access simply doesn't have. To take your excursion to the next level, here are some learning resources:
| Resource | Description |
| Video-based course | |
| Ttutorials about SQL Server 2017 | |
| Hands on learning for Azure | |
| Become an expert | |
| The main landing page | |
| Help information | |
| Help information | |
| An overview of the cloud | |
| A visual summary of new features | |
| A summary of features by versions | |
| Download SQL Server Express 2017 | |
| Download sample databases |
Microsoft Office Tutorials: Take An Access Excursion Through Sql Server >>>>> Download Now
ReplyDelete>>>>> Download Full
Microsoft Office Tutorials: Take An Access Excursion Through Sql Server >>>>> Download LINK
>>>>> Download Now
Microsoft Office Tutorials: Take An Access Excursion Through Sql Server >>>>> Download Full
>>>>> Download LINK 1k